Author: miriamleon8
MoneyMaid: a transaction categorization tool
During my time at Insight I completed a consulting project with wallet.AI. The project involved data cleaning, natural language processing and a multiclass classification.

During my time at Insight I consulted for a startup called wallet.AI. Wallet.AI builds intelligent engines to help people make better day-to-day money decisions. Wallet.AI connects to your bank and provides you with insights about how to improve your financial behaviour. For example, once it has analysed your transactions it will be able to inform you that you managed to save $100 because you didn’t go to restaurants as much last month.
An integral part of this process is the successful identification and categorisation of each transaction found on a bank statement. Wallet.AI needs to be able to break down a user’s transactions into categories such as food, bills, income etc in order to provide certain kinds of insights to its users. So if you bought a coffee from Blue Bottle Coffee, it needs to be able to identify that that is a coffee shop. This is where my project lies.
Digging into the dataset
I worked with a dataset of 7600 transactions, classified by a third party into 92 classes. An overview of the categories in the dataset is:

I first trained a Random Forest classifier to classify each of these transactions into the predefined set of categories. This achieved an accuracy of 58%, which is much lower than I would like! Going back to the dataset, I went through the categories and noticed that the given categories weren’t a useful set: 17% of the data was categorised as ‘Uncategorised’ and there were also redundant categories, like ‘Clothing’ and ‘Shopping’. A merchant like Gap could be classified into either correctly but that would throw off the accuracy metric. There were also typographical mistakes in the categories: There is a category label for ‘Fast food’, one for ‘Uncategorized’ as well as one for ‘Personal Care; Restaurants’.
So the first thing I did was to use a different, more useful set of categories. For that I took the categories used by a popular budgeting app. This new set eliminated redundant categories and simplified the classification problem from 92 to just 22 classes:
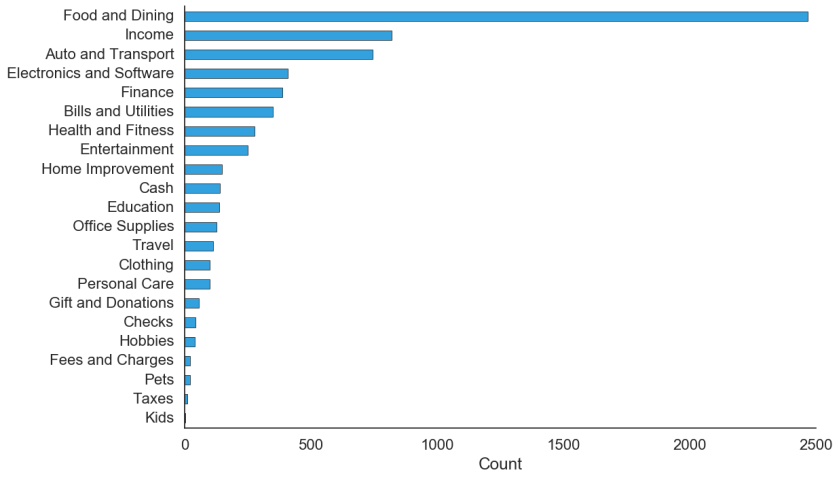
I then hand labelled the dataset with the new set of categories, in order to establish a ground truth for the classification. Each transaction was labelled with two levels: a subcategory and a parent category (the parent categories are shown above). For the purpose of this project I used the parent categories but the more granular subcategories are available to wallet.AI for the future.
Extracting Information
I then began to build the features that will be used for the classification. The data I had available was in the form of unstructured data and numerical data, all related to information about each transaction. In order to extract features from the unstructured text data I used natural language processing:

The strings of unstructured text were first cleaned of any stopwords, symbols and numbers. The preprocessed text was then converted into vectors by using the GloVe pretrained model. http://nlp.stanford.edu/projects/glove/
The value of transaction was also used as a feature as well as the tax code if that was given. This all resulted in 303 features to use for classification
Model
In order classify the transactions into the 22 classes I used a Gradient Boosting Classifier. A decision tree is ideally suited for such a multiclass classification problem, especially when unbalanced classes are present. Given the features I had available, they constituted a large number of weak learners, so a boosted algorithm will perform better.
I first split the dataset into a training set and a test set, at 75% and 25% of the dataset respectively. I optimized the parameters of the model by using a grid search method to select for the combination of parameters that maximize model accuracy on the training set.
As the classes were imbalanced, I used oversampling of the minority classes on the training set. After training the model, I tested its performance on the test set and achieved a 96.1% accuracy, with 96% precision and 96% recall. The detailed classification report is shown below:
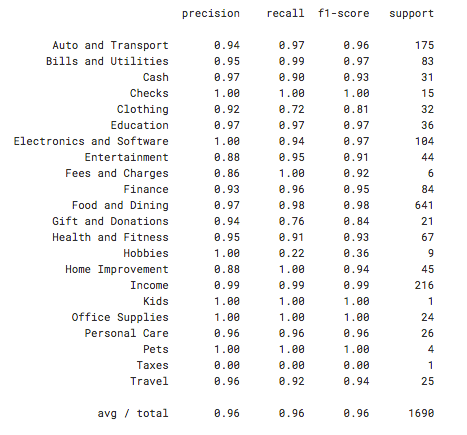
Insights
Now that the dataset had been cleaned and could be successfully classified, I went back to see how I can use this data to help wallet.AI help its users better.
One question I could ask is, which are the categories most ripe for intervention? My hypothesis was that these would be the categories where the transaction values were small but frequent. This is because, these are the transactions that a consumer might think are harmless and would be the hardest to keep track of. $3 here and there feel like spare change, but if this occurs frequently enough they could add up and can make a real difference to a user’s finances.
In order to identify these categories, I plotted the mean value of a transaction per category against the mean number of transactions found in each category, averaged over all users.
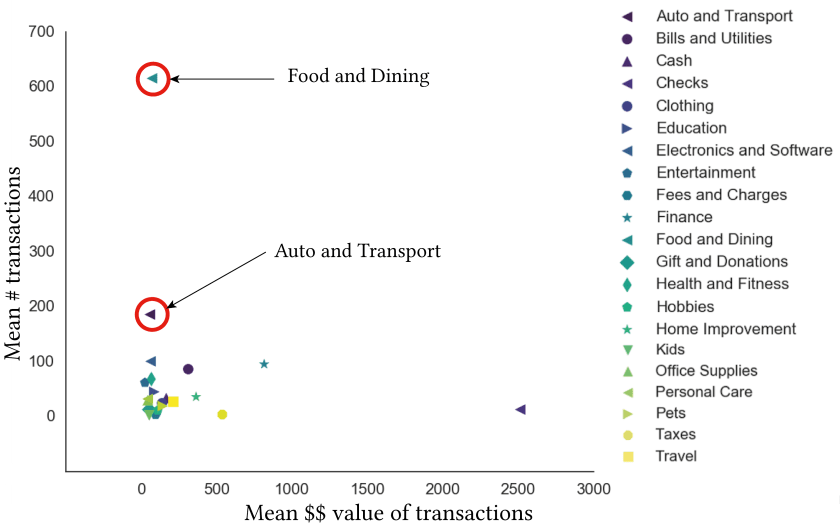
Using this plot, I can identify that Food and Dining is the category most ripe for intervention. Even if that $3 coffee a day seems harmless, wallet.AI could tell you that by reducing that, a user might save a significant amount of money. Such an analysis could help identify the categories wallet.AI might address first when onboarding a new customer, as these could create maximum impact much faster in the improvement of that customer’s financial life.
Final Thoughts
This was a great experience of not only familiarising myself with what transaction data looks like, but also to learn how to handle unstructured text for machine learning. Natural language processing is a technique I was always eager to learn and this was the perfect opportunity.
I delivered to wallet.AI a classification algorithm that can achieve 96.1% accuracy. This dramatically improved the current baseline and can be easily retrained as additional, previously unseen data is added to the dataset.
Finally, I used a quantitative way to identify the categories that are most ripe for intervention. This could help wallet.AI identify the categories that can be addressed first. Wallet.AI were pleased with these results and will work into incorporating them into their workflow.
